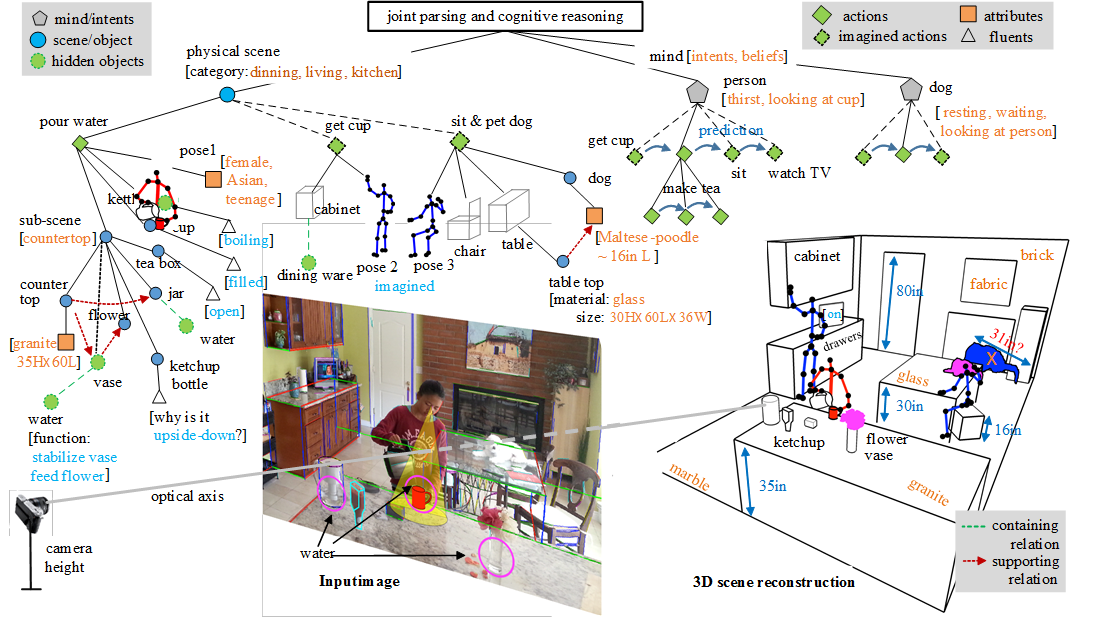
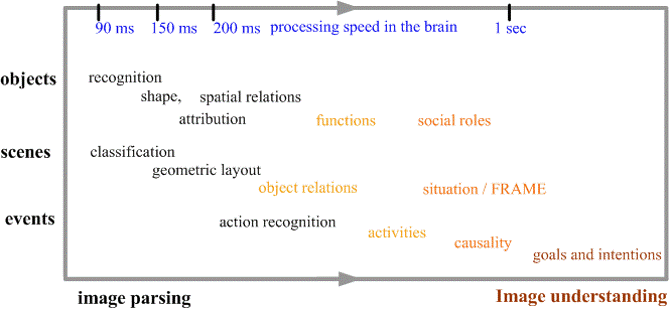
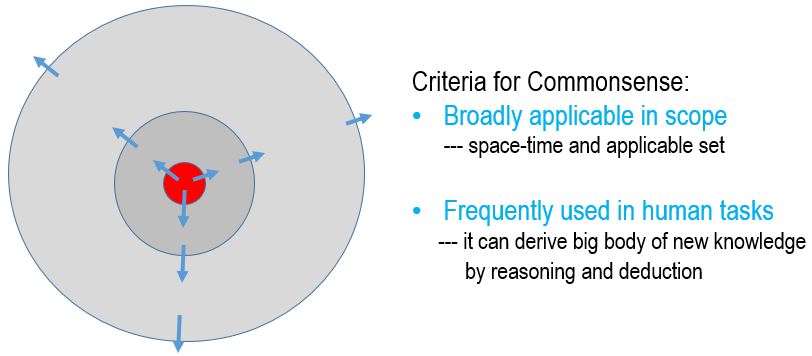
Vision is arguably one of the most challenging, and potentially useful, problem in modern science and engineering for its enormous complexity in knowledge representation, learning and the computing mechanisms of the biologic systems. For such a complex problem, we must look for a long term solution, and be cautious that many apparently promising ways may lead to dead ends. By analogy, suppose some monkeys want to reach the moon, they may choose to (1) climb a tree, indeed, a tree could be so tall that a monkey climbs diligently for a life time, (2) grab the moon from a well at night time, or (3) ride a hot air balloon! All these methods appear to be smart and actually very cute, and people can enjoy measurable progress over time! while the real solution (building a spacecraft) looks hopeless for a long time and appears to be totally ridiculous to ordinary eyes ! In reality, most people simply do not have the patience to learn astrophysics and rocket science, which are too complex and boring for them.
—— Comic illustrated by my daughter Stephanie Zhu (11 yrs old drawn in 2010): How to reach the moon.